局部刷新模板那些事
模板是每个前端工作者都会接触到的东西,近几年前端的工程化,发展的如火如荼。从基本的字符串拼接到字符串模板,再到现在各种框架给出的“伪模板”解决方案,前端模板经历了种种变革。
下面就不同时期的模板做一下回顾。
本文假定读者已经对
underscore,mustache,angularjs,reactjs等技术有了一定的了解。否则请先看看相关资料了解下。
原始的模板
提到模板,不得不提到每个前端都会经历的字符串拼接的阶段。
看下面这段代码:
<ul id="test">
</ul>
<script>
var students = [{
name:'张三',
age:'19'
},{
name:'李四',
age:'17'
},{
name:'王五',
age:'21'
}]
var htmlArray = [],tmplStr
for(var i=0;i<students.length;i++){
tmplStr = '<li>'
tmplStr += '姓名:'+ students[i].name +'年龄:' + students[i].age
tmplStr += '</li>'
htmlArray.push(tmplStr)
}
document.getElementById('test').innerHTML = htmlArray.join(' ')
</script>
代码逻辑很简单,将一份数据循环拼接好字符串最后组装好html字符串塞到页面上。
可以看到这种写法,模板部分跟逻辑部分很容易耦合在一起,非常的不清晰,可读性也很差。在大规模项目中是不建议这么用的。
字符串模板的兴起
因为上面的写法有太多的缺点,所以先辈们开始实现基本的模板引擎。实现展示与逻辑的分离。
比较典型的是underscore类型的模板,它其实很简单,就是把一个基本的模板语法转换成一个可执行的javascript代码。
我们看下上面的功能使用underscore的语法怎么写:
<ul id="test">
</ul>
<script>
var students = [{
name:'张三'
},{
name:'李四'
},{
name:'王五'
}]
var tmpl = '<% for(var i=0;i<students.length;i++){ %> 姓名: <% students[i].name %> <% } %>'
//假设template可以实现类似underscore的语法
var tplCompile = template(tmpl) //先生成执行函数
document.getElementById('test').innerHTML = tplCompile(students)//执行渲染
</script>
template,作为实现了underscore功能的函数,传入一个模板还有一份数据,就可以把模板渲染出来。
这样写的好处是,实现了模板与字符串逻辑的分离。ui层,也就是渲染逻辑看起来会比较清晰。
下面我们来看看如何实现一个最基本的template:
function template(tpl){
//用来匹配出我们的特殊语法
var tplReg = /<%([^%>]+)?%>/g
var match;
var cursor=0;
var regOut = /(^( )?(if|for|else|switch|case|break|{|}))(.*)?/g;
//需要拼接的代码,这里注意with的用法,用来使渲染的数据应用在模板里
var code = 'var codes=[];\nwith(renderData){\n';
var addLine = function(line,js){
//普通文本,这时候加上一个双引号就可以了
if(!js){
code += 'codes.push("' + line.replace(/"/g, '\\"') + '");\n'
return
}
//特殊语法特殊处理
//对于有js特殊逻辑比如for,if这种代码,不适用push。直接打出。
if(regOut.test(line)){
code += line + '\n';
}else{
//普通的特殊语法,跟上面的普通的文本唯一的区别就是少了双引号,这样以后执行时就会是变量。
code += 'codes.push(' + line + ');\n'
}
}
//通过正则不停的去匹配特殊语法
while(match = tplReg.exec(tpl)) {
//截取前面的普通文本
addLine(tpl.slice(cursor, match.index)); //普通文本
//将当前的特殊语法加入
addLine(match[1],true); //特殊逻辑
cursor = match.index + match[0].length; //更新游标
}
//末尾可能还剩下些语法
addLine(tpl.substr(cursor, tpl.length - cursor)); //剩下的代码
code += '};return codes.join("")';
code = code.replace(/[\r\t\n]/g, '')
var compileFn = function(data){
//使用function执行拼好的代码,将data传到函数里。
return new Function('renderData',code)(data);
}
return compileFn
}
实现很简单,主要就是通过正则替换,拼凑出最终的js执行语句,然后使用function来执行得到结果。
我们通过tplReg这个正则匹配出所有的<% ... %>特殊语法,addLine负责生成javascript可执行语句。
addLine添加的语句需要分三种情况:
- 特殊语法之外的普通文本,比如上面的
姓名:这种文本。这个时候直接push到codes里面就行,最后会原样输出。这边需要加上双引号代表是个普通字符串。 - 对于特殊语法里面的普通语法,比如上面的
students[i].name,这种时候直接push到codes里面,跟上面不同的是,这时不需要加双引号,这样最后这些codes执行时就会把它作为变量去处理。 - 还有一种特殊的语法,就是
for(var i=0;i<students.length;i++){这种带for的
。这个时候不能放到codes里面,因为我们本身需要它的循环功能。
最后拼接好codes后,使用function一次执行得到最终渲染好的字符串。
当然我们这边的实现超级简陋,仅供参考原理。实际的模板还需要考虑缓存,兼容性,xss等等。
字符串模板使用很广泛,也踊跃出了若干实现。mustache,Underscore templates,Dust.js等等,前端真的是能折腾。如果有选择困难症,可以看看这里:http://garann.github.io/template-chooser/
这个阶段的模板或多或少都是相同的原理。
- 解析字符串模板,有的是直接正则分析,有的是用语法树分析。
- 渲染出结果,直接改造成原生的javascript语句执行拿到结果。
这在很长一段时间里对于前端工程师来说已经够用了。通过模板的dsl,很好的实现了前端逻辑与ui的分离。
字符串模板的局部刷新
但是随着前端的发展,特别是富客户端应用的兴起。单纯的字符串模板已经很难满足需求了。
比如一个学生个人信息界面,分为个人姓名,还有个人成绩两块。
<div>个人信息:</div>
<div id="test">
</div>
<script>
var student = {
name:'张三',
score:89
}
var tmpl = '<div>姓名: <% name %> </div><div>成绩: <% score %> </div>'
//假设template方法可以实现underscore的语法
document.getElementById('test').innerHTML = template(tmpl)(student)
</script>
如果我们初次渲染后需要去更新成绩。我们期待的情况肯定是只更新成绩,个人姓名不要重复刷新。这对于普通字符串模板是做不到的。只能自己使用dom操作去修改,而这样就违背了我们的初衷,逻辑又跟展现耦合变的不可控了。
实际情况会更复杂,页面内容更多,需要局部刷新的地方更多,这里为了方便,只举一个最简单的例子。
如果不自己使用dom操作,还希望用模板,那么每次要改点东西都需要整个页面全部重新渲染,在通过innerHTML一次性更新。
- 首先这会造成页面的整体刷新,用户体验差
- 其次,每次innerHTML,浏览器都需要重新渲染dom结构,造成性能浪费
我们其实是需要一种局部刷新的东西,在初次渲染后仍然保持模板与dom的联系。通过一些方法,只改变页面中的一小部分html。差异化的去更新。其实是一种innerHTML的优化。
我们团队很久之前就做了这方面的尝试,可以先看下我们是怎么用的:
<script>
var student = {
name:'张三',
score:89
}
//注意下面的模板里面多了 tpl-name="sc" tpl-key="score"
var tmpl = '<div>姓名: <% name %> </div><div tpl-name="sc" tpl-key="score">成绩: <% score %> </div>'
//第一次渲染,会自动绑定到test的div上
var node = render('test', tmpl, student)
//如果我们需要更新成绩只需要调用setChunkData来局部刷新页面
node.setChunkData(score,100)
</script>
首先我们会在需要更新的局部dom上打上标签tpl-name="sc" tpl-key="score",代表这里的dom第二次渲染需要依赖score这个变量,并且这个局部模板有了唯一标识sc。然后当我们需要更新成绩的时候只需要调用node.setChunkData(score,100)就可以找到依赖score这个变量对应的dom并且自动使用局部模板去刷新页面了。
可以看到这样带来了不少好处,我们可以继续享受模板带来的便利性,也可以局部刷新页面中的某个区块。而这一切都是建立在数据上的,我们的逻辑处理永远在数据这一层,面向数据编程。而渲染,局部渲染都会自动帮忙完成。
那么达到这样的功能我们需要做什么呢?
- 首先我们需要先解析模板,对于
tpl-key这样的标签,我们需要特殊处理,把子模板记录下来,并且记录tpl-name,作为对应。 - 在调用setChunkData时,我们需要去找到对应的局部模板,还有对应的dom。重新渲染后局部innerHTML。
我们看一个最简单的实现(基于上面的template增强而来):
//此函数依赖上面的template函数
var render = function(id, tpl,data){
//初次渲染,直接使用以前的template函数
document.getElementById(id).innerHTML = template(tpl)(data)
//下面都是局部渲染需要的逻辑
var tpls = []//存放局部刷新的模板
//解析模板,找到局部模板 这边的getSubTpls可以先不管,只需要知道返回结果为:
//[{name:'sc',key:score,tpl:'<span>成绩:</span> <% score %> '}]
tpls = getSubTpls(tpl)
//用于根据依赖的key找到对应的那些模板
function getChunkTpl(key){
var results = []
for(var i= tpls.length-1;i>-1;i--){
if(tpls[i].key === key){
results.push(tpls[i])
}
}
return results
}
return {
setChunkData:function(key,value){
var subData = {}
subData[key] = value
var subNode
var subTpls = getChunkTpl(key) //匹配到对应的局部模板,可能有多个
for(var i=0;i<subTpls.length;i++){
//这里为了图方便直接用querySelector了
subNode = document.querySelector('[tpl-name="' + subTpls[i].name + '"]')
//渲染好,刷新局部dom
subNode.innerHTML = template(subTpls[i].tpl)(subData)
}
}
}
}
基本实现了我们需要的功能,逻辑上也不复杂,提前准备好局部模板,在setChunkData时通过key找出对应的局部模板还有dom节点,这样就可以达到局部刷新的目的。
下面看下getSubTpls的实现,这个如果不感兴趣可以直接跳过,毕竟已经是过时的技术了。
//这个方法是用来获取一个tag下面的字符串
//getTagInnerHtml('<div><span></span><div id='1'></div></div>',div,0,0)
//可以匹配出<span></span><div id='1'></div>
function getTagInnerHtml(tpl, tag, s_pos, offset) {
var s_tag = '<' + tag
var e_tag = '</' + tag + '>'
var s_or_pos = s_pos + offset
var e_pos = s_pos
var e_next_pos = s_pos
s_pos = tpl.indexOf(s_tag, s_pos)
var s_next_pos = s_pos + 1
while (true) {
s_pos = tpl.indexOf(s_tag, s_next_pos);
e_pos = tpl.indexOf(e_tag, e_next_pos);
if (s_pos == -1 || s_pos > e_pos) {
break
}
s_next_pos = s_pos + 1
e_next_pos = e_pos + 1
}
return {
html: tpl.substring(s_or_pos, e_pos)
}
}
function getSubTpls(tpl){
//用来匹配带有标签的tag的正则
var tplTagReg = /<([\w]+)\s+[^>]*?tpl-name=["\']([^"\']+)["\']\s+[^>]*?tpl-key=["\']([^"\']+)["\']\s*[^>]*?>/g
var match,tagInfo
var tpls = []
while(match = tplTagReg.exec(tpl)) {
tagInfo = getTagInnerHtml(tpl,match[1],match.index,match[0].length)
tpls.push({
name:match[2],
key:match[3],
tpl: tagInfo.html
})
}
return tpls
}
关键是getTagInnerHtml的实现,由于javascript没有平衡组的概念,所以不得不写这么一长串的处理逻辑,具体参考
http://lf-6666.blog.163.com/blog/static/3123705200942155416430/
http://thx.github.io/brix-core/articles/tpl-3/
至此基本功能就完成了。在一段时间里也够用了。
实际的代码,需要处理的问题更多,需要处理好父子级局部模板,多个数据并列依赖等等问题,由于已经是过时的技术了,这里就不详细展开了,有兴趣的可以到这里了解。
但是其实还是有些显而易见的问题:
- 局部刷新需要自己去指定标签,也很难处理父子包含,同级数据并列等问题
- 使用
setChunkData私有方法,需要到模板找到对应的依赖数据,需要自己去把握逻辑 - 局部刷新其实只是局部的innerHTML,有的时候没法力度太细。跟真正的dom操作比起来,消耗、闪烁都是要大的。
这个时候我们渐渐发现字符串模板已经走到头了。面对日新月异的前端开发,尤其是单页应用,普通的字符串模板已经不能满足需求了。
新时代的“模板”
因为字符串模板的种种缺陷,在新的大时代背景下,尤其是前端各种框架的井喷时代。各种各样的框架实现了很多很有意思的东西,跳出了传统字符串模板的概念,但是的确实现了模板的功能。这个时候已经不适合称之为模板了。
我们先想想,我们上面探索局部刷新时遇到了什么问题。
首先我们需要保持跟模板的联系,这样我们下次需要局部刷新时才能找到对应的节点。比如我们上面是通过在dom节点上打标来实现的。
其次我们需要监听数据的变化,我们上面是直接使用私有方法setChunkData来通知引擎数据变化了,可以开始更新了。这样其实很不好,需要我们关注太多的东西。
另外如果我们多次调用setChunkData,那么就会渲染多次,除了最后一次前面的渲染都是没有必要的,所以我们还需要个批量更新的东西,前面的那些改动不需要真实的反应到dom上。
事实上,目前的主流框架虽然已经脱离了模板的范畴,但是也是紧紧围绕这几个方面来实现的。
当然目前还兴起了双向绑定的热潮,不过在传统的字符串模板里是难以实现的。
下面我们大概介绍下主流的几个框架的是如何实现模板功能的,具体分为下面这几点:
- 如何监听数据的变化
- 如何渲染更新页面定位节点位置
- 初次渲染的逻辑
- 后来的更新机制
- 如何实现双向绑定
- 如何实现批量更新
angularjs
angularjs带来了很多前端界的新概念,指令,脏检测,filter等等等。
原理
我们看下angularjs的大致图形
几个概念:
- watcher 用来监听一个表达式的变更,然后有一个回调。
- directive 具有link方法,存放所有的指令逻辑。一般会使用watcher的功能。
- scope 作用域,angular的所有方法,数据都会在这个上面。
- digest 用来执行脏检测,开始递归检查scope上的所有watcher发现当前的值跟以前的不一样时就做出dom改变。
三个大模块:
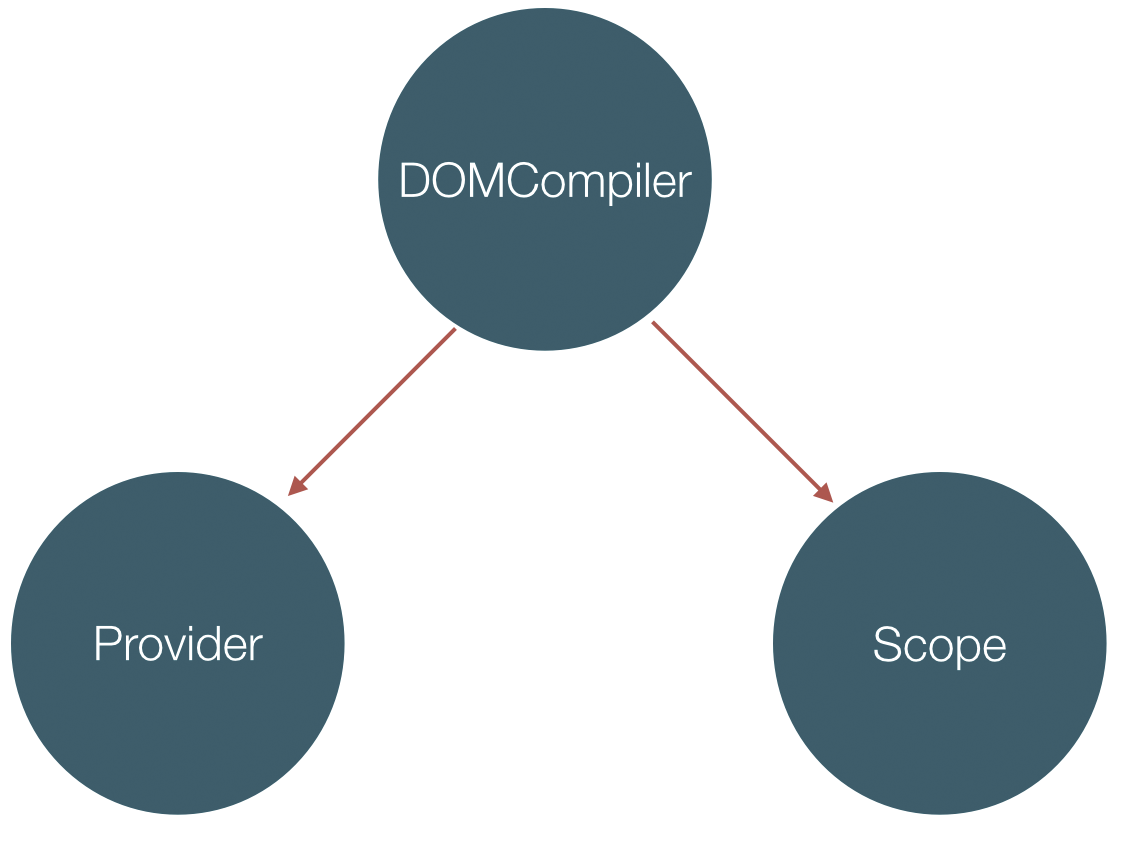
Provider:
- 注册组件(directives, services 和 controllers)
- 解决各个组件之间的依赖关系
- 初始化所有组件
DOMCompiler:
- 遍历dom树的所有节点
- 找到注册的属性类型的directives指令
- 调用对应的directive对应的link逻辑
- 管理scope
Scope:
- 监控表达式
- 在每次$digest循环的时候执行所有的表达式,直到稳定,稳定就是说,表达式的值不再改变的时候
- 在表达式的值发生改变时,调用对应的所有的回调函数
怎么串起来:
<span ng-bind="a + 'hello'"></span>
我们看看ng-bind这个指令的实现:
Provider.directive('ng-bind', function () {
return {
link: function (el, scope, exp) {
//初次渲染的逻辑
el.innerHTML = scope.$eval(exp);
//添加一个观察者,当在下一次脏检测发现数据改变时就执行回调逻辑
scope.$watch(exp, function (val) {
el.innerHTML = val;
});
}
};
});
初始化时:DOMCompiler遍历dom节点,找到指令定义,执行link,写dom。并且通过scope的方法增加watcher观察者。
更新时:调用scope的digest,这个时候会遍历所有watchers,拿新的值跟旧的值做对比,如果不同就执行回调。
所以对于我们这边的简单例子来说,第一次初始化时,通过link函数我们第一次使用innerHTML来渲染dom。同时添加了一个watcher,这样在框架下次脏检测时,检测到数据变化就会调用回调里的逻辑,这里就是重新innerHTML。
具体可以看看这篇文章了解下它内部的渲染逻辑。
当然这里只是给出了最简单的实现,其实这类模板的难点在于for,if这种指令的实现。这里受限于篇幅就不详细展开了。
分析
所以,angular的局部刷新,就是通过指令的私有逻辑来实现的。提出了一些比较好玩的概念。
我们再对比下之前说的那几个点:
如何监听数据的变化:通过脏检测,用户在代码中调用
scope.$digest()方法,在angularjs里面框架会在某些时候帮你调用。脏检测会负责遍历scope上面的所有观察者watcher。对比表达式的上一次值与现在的值,如果发现数据变化就会调用添加的回调逻辑。如何渲染更新页面定位节点位置:通过指令,本身已经有了dom引用,一些特殊情况,会使用注释节点做占位符。
如何实现双向绑定:实现model指令,监听数据改变后先修改data数据,之后调用digest来一次脏检测更新就行了。
如何实现批量更新:脏检测本身就是批量的,因为是一次性调用digest才开始统一检查数据变化。
优点
- angular大而全,功能特别强大。集成了很多概念,社区也比较强大。
- 开发体验比较好。模板里的expression使用了自己的编译器去解析,所以支持很强大的语法。
- 提出了很多很好的概念,如filter,watcher。
缺点
- 很多功能不需要,难以单独拿出来跟业务结合
- 脏检测导致的性能问题,特别是大列表的局部刷新情况,watcher太多,导致性能巨差
- 直接解析现有dom带来不少问题,闪烁,属性错误等等
- 页面有多个实例时会经常出现脏检测的冲突
- 指令的写法,相对于传统的字符串模板,可读性差
vuejs
vue在学习angular的基础上,做了些精简还有优化。vue只负责处理view,其实是模板+组件方案+动画。我们这里主要看他的模板方面的原理
原理
原理其实类似,也是有指令还有watcher的概念,只是去掉了scope,去掉了脏检测而是使用get set来做数据的变化监听。

首先你需要先了解下defineProperty,这个特性,可以达到在你对一个属性读或者写的时候写上自己的钩子函数。
整个原理是这样:
- 先给数据注入get,set。递归注入,这样可以注入自己的钩子逻辑。
- 第一次compile的时候,找到页面上的指令,并且初始化指令,同时new一个watcher,第一次获取值。获取值的时候,触发get的钩子。这样就把key跟对应的watcher绑定起来。
- watcher的回调不像angular那样自己写自己的私有逻辑,而是默认都是调用指令的update方法。
- 所以指令也是不同的,vue的指令有bind,update,destroy三个方法,分别负责初始化,更新,销毁需要做的事情。
- 当用户修改了值,会触发set,这样会通知对应绑定的watcher进行两次数据的校验,不同就触发回调,也就是对应指令的update方法。
可以看到跟angular不同的地方主要在于,指令职责更细,另外有暴力的全部watcher检测,变成了通过set的钩子来指向性的找到对应的watcher做数据变更检测。所以在更新性能上会明显优于脏检测。
具体原理可以参考:http://cn.vuejs.org/guide/reactivity.html
还有:http://jiongks.name/blog/vue-code-review/
分析
- 如何监听数据的变化:通过defineproperties注入钩子,修改了数据就会出发钩子,然后通知对应的watcher进行检测
- 如何渲染更新页面定位节点位置: 也是通过指令,本身已经有了dom引用。而且vue很创新的使用了空白节点来占位。
- 如何实现双向绑定: 实现model指令,也是有私有逻辑,监听dom改变后,修改对应的data,钩子会自动触发完成更新。
- 如何实现批量更新:vue使用settimeOut,延迟watcher的check。通过去重watcher。达到批量更新的目的。当你多次调用赋值时不会立即去check数据的变更,而是在一次setTimeout后,开始检测队列。
特点
- 相对angular来说,职责更清晰,去掉了很多不必要的东西,更加轻量
- 使用defineproperties解决了脏检测的性能问题,从暴力全量检测变成了指向性的检测
- 提出了空白占位节点的概念,解决了angular里面一堆注释节点的问题
- 动画功能很强大
缺点
- defineproperties必须提前写好属性,侵入的改写get set。
- 不支持ie8
- 直接解析dom节点,(造成额外的404请求,一些写法有问题。因为提前渲染)
- 一直保留着对dom的引用。是否是一种浪费
- 初次渲染并不会比脏检测快,因为需要各种递归的注入。
- 指令写多了模板可读性太差。
- 暂时没有服务端渲染方案,因为依赖dom。
其实这些缺点也都是angular会有的缺点,可以说vue已经解决了大部分的angular会有的问题。不过为了使用defineproperties放弃了支持ie8,对于国内的环境来说,ie8还是难以割舍。
reactjs
reactjs创造性的提出了虚拟dom的概念,完全改变了前端的开发方式
原理
react,其实就是虚拟dom与真实dom的互动。
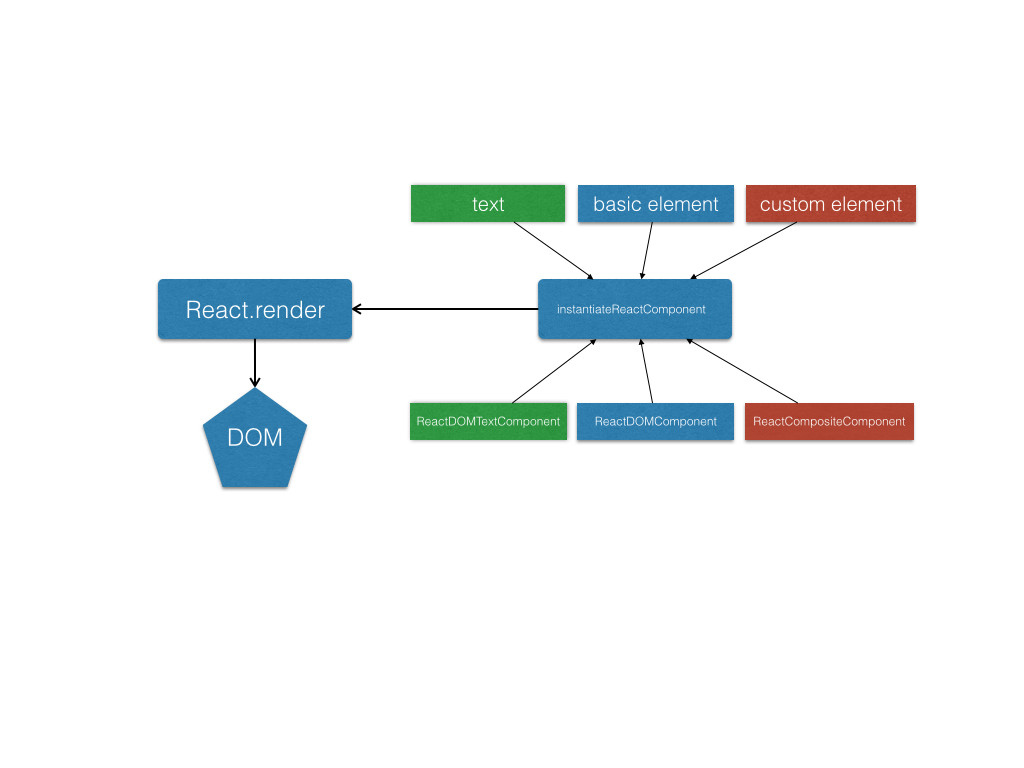
最上面的text,basic element,custom element都是我们通常说的virtual dom。我们先不管红色的自定义组件节点custom element。
每一个virtual dom都有一个对应的Component来管理。Component具有两个方法:mountComponent还有receiveComponent分别负责处理初次渲染还有更新的逻辑。
react初次渲染就是拼接出字符串。每种virtual dom会调用自己的Component对应的mountComponent来得到渲染之后的内容。比如对于text就直接返回个span包裹的文本,对于basic element,需要先处理自身属性,再调用子节点对应的Component的mountComponent,最后全部拼接好,一次性的innerHTMl到页面上。
更新的时候,react里面一般是通过setState来赋予一个新的值,这样内部再调用receiveComponent来处理逻辑。对于basic element,就是先更新属性,再去更新子节点。这里有套算法,能复用的就直接调用子节点的receiveComponent。否则就是一次重新的mountComponent渲染(diff,patch)。对于text节点,直接是innerHTML更新。
具体原理参考:http://purplebamboo.github.io/2015/09/15/reactjs_source_analyze_part_one/
分析
如何监听数据的变化:很原始的get set(setState),跟我们最上面的
setChunkData类似如何渲染更新页面定位节点位置:不需要直接引用真实dom,引用虚拟dom就行。虚拟dom根据id来跟真实dom一一对应。
如何实现双向绑定:原生不支持双向绑定,不过有插件形式的替代方案。
如何实现批量更新:执行方法时会包裹一个batchUpdate。这样所有的setState会执行完以后再统一去diff。
特点
- 创造性的提出了virtual dom的概念
- 支持服务端渲染
- 通过dom的diff,加快了更新速度
缺点
- 本质上还是脏检测,虽然这个脏检测是可以优化的
- 其实不存在模板语法,if,for都是要写js代码。理解起来很困难。
- 全家桶没办法跟其他的技术结合
- 不允许自己修改dom
思考
不管是 angularjs,vuejs,或者是reactjs,总感觉用起来不是那么顺手,原因是我们已经习惯了传统意义上的模板写法。所以这种dom based的模板总会有这样那样的限制,导致我们不能很顺畅的去开发。
上面这几种,目前我是比较喜欢vue的设计理念的,但是它也有着我们难以接受的缺点。不能说vue不优秀,只是的确不适合我们的业务。
那么我们是不是可以改造下,是否可以结合virtual dom 跟 指令的优势?
vue的指令是直接操作dom的,如果加一层virtual dom,实现大部分dom方法。让指令引用virtual dom,由virtual dom来操作真实dom。这样其实就可以解决掉vue的大部分问题。
我们可以先把模板解析成一个ast(抽象语法树)结构的虚拟dom树。然后去解析这个树,分析出各种依赖信息。这比vue直接使用原生dom会好很多。
指令不会直接跟dom打交道,而是跟虚拟dom打交道。
对于初次的渲染来说,各个指令会调用虚拟dom的方法,此时虚拟dom知道是初次渲染,所以只会更新自己,而不会修改真实的dom。在最后全部执行好后,一次性的innerHTML到页面中。有点跟react类似?
而更新的时候,仍然是指令的逻辑,只不过这个时候虚拟dom不仅仅会更新自身,也会同时更新真实的dom。
可以看到因为加了一层虚拟dom,解决了很多问题。
我们的基本原理还是vue的原理,但是通过一层中间虚拟dom层。我们可以做到:
- 可以把模板的解析前置到打包阶段。打包出虚拟的virtual dom,像react那样,而vue是放到一个documentfragment,先渲染再改动。
- 初次渲染不再依赖真实dom,从而使服务器渲染可以像react那样变得比较简单。
- 因为不依赖dom,所以不会出现vue那样的非法指令的问题。
- 因为有一层中间dom。所以理论上可以支持任何语法,只要后面打包时转成虚拟dom的语法。
所以 我做了pat,在vue的基础上加上vd的概念,当然还支持了ie8等等,为了支持业务做了一些改动。
一句话概括pat:
listener(defineProperties/dirtycheck) + directive + virtual dom
地址:http://purplebamboo.github.io/pat/doc/views/index.html
与目前主要的框架相比,pat具有以下特点:
- 单一职责,pat只负责解决模板问题。使用者可以单独使用,也可以跟任何其他框架结合使用。
- 支持类mustache风格的模板语法,避免了指令写多了模板可读性差的问题。
- 具有指令型框架的特点,扩展性强,功能强大,可以扩展自己的指令。同时支持filter与自定义watcher。
- 具有virtual dom中间层,一方面加快了分析指令的速度,另一方面也为服务端渲染提供了可能。还解决了错误属性的问题。而且没有强引用。
- 考虑到目前国内情况,pat做了大量事情,兼容到了ie8。
- 同时支持脏检测与defineProperties的数据检测机制。在defineProperties模式下使用vbscript来做ie8兼容处理。
结语
目前的前端界各种框架满天飞,但是都或多或少的有所缺陷。有句话说的好,没有最完美的方案只有最适合的自己的方案。
在这样的背景下作为一个前端遇到问题该怎么办呢,我认为可以先找开源技术,但是当开源技术不能满足自己的需求时。可以在开源技术的基础上修改加上自己的东西从而更好的解决问题。
其实把模板解析成ast已经有很多框架在做了。都是看重了virtual dom的优势。比如下面这些:
- htmlbar: 运行在handlebar之后的二次编译
- ractivejs: 也是分析成虚拟dom
- Regularjs: 网易的框架,在angular基础上改造而来
- diff-render: facebook的人开发的,可以直接diff两个渲染好的字符串的差异,然后去更新。本质上每次都会解析成虚拟dom,然后像react那样diff这两个虚拟dom树
总之前端的轮子真的太多了,但是无外乎那些解决方案,我们要做的就是了解这些方案,找到合适自己的,当没有特别合适的就拿一个加以改造解决自己的问题(于是又会造个轮子= =)。
相关引用
- http://div.io/topic/636
- http://www.liaoxuefeng.com/article/001426512790239f83bfb47b1134b63b09a57548d06e5c5000
- http://www.cnblogs.com/hustskyking/p/principle-of-javascript-template.html
- http://www.html-js.com/article/Regularjs-Chinese-guidelines-for-a-comprehensive-summary-of-the-front-template-technology
- http://www.toobug.net/article/how_to_design_front_end_template_engine.html
- https://www.zhihu.com/question/32524504
- http://ejohn.org/blog/javascript-micro-templating/
- http://nuysoft.com/bak/templating.html